ブログ


Continue で実現する LM Studio × VS Code のローカルLLM環境
こんにちは、T.Oです。
GoogleのGemma 4やAlibabaのQwen 3.6等が登場し、ローカルLLMでもコーディング用途で十分に使えるようになってきたという話を耳にしたので、実際に試してみました。
クラウドAIに頼り切りの状態を一度見直したかったことと、社外秘コードを扱う案件でも使えるかどうかを確かめたかったことです。今回はLM StudioとVS CodeのContinue拡張機能を組み合わせ、構築の手順から実際に使ってみた感触までを記録していきます。
目次
必要な環境:LM Studio、VS Code、Continue
今回の構成は、ざっくりこの3つの役割分担です。
- LM Studio … ローカルでLLMを動かすサーバー本体です。モデルのダウンロードから推論サーバーの起動までGUIで完結します。
- VS Code … コードエディタです。
- Continue … VS Code側の拡張機能です。LM Studioが立てたサーバーを叩き、サイドバーやインライン補完から使えるようにします。
LM Studio
公式サイトから最新版をダウンロードします。安定版で問題ありません。
macOSのApple Silicon版・Intel版、Windows版、Linux版が用意されているので、
環境に合わせて選んでください。
VS Code
公式サイトからダウンロードしてください。すでに入っている方はそのままで大丈夫です。
Continue
VS Codeの拡張機能マーケットプレイスで「Continue」と検索し、「Continue – open-source AI code agent」をインストールします。
似た名前の拡張機能がいくつか並ぶので、提供元が continue.dev のものを選んでください。
LM Studio側の設定:モデルのダウンロードとサーバー起動
モデルをダウンロードする
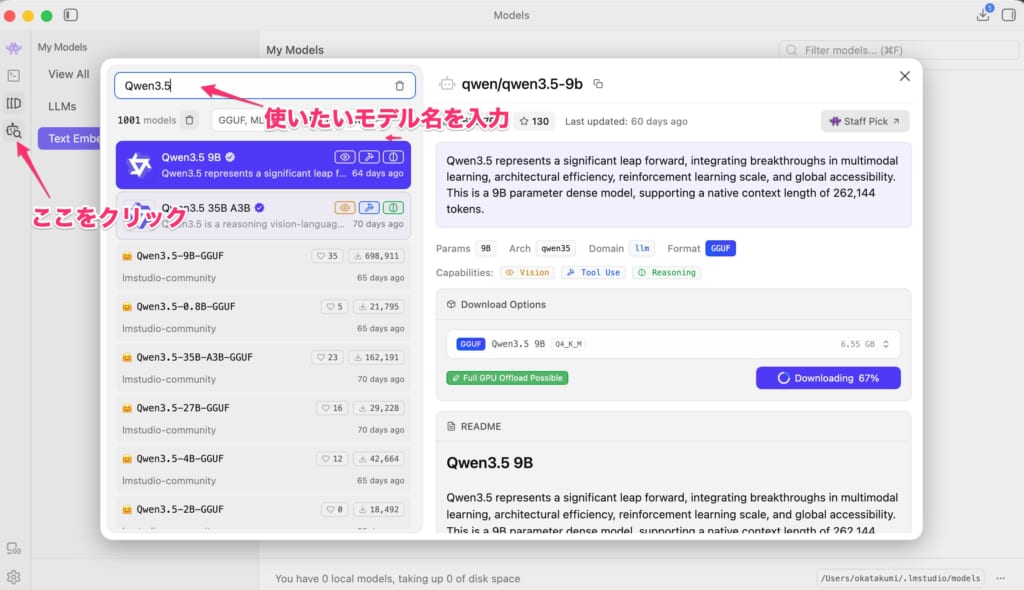
LM Studioを起動したら、左メニューの虫眼鏡アイコン(Discoverタブ)を開きます。
検索バーにモデル名を入力すると、Hugging Face(AIモデルが集まる共有プラットフォーム)から取得したモデルの一覧が表示されます。
モデル選びは、お使いのマシンスペックに応じて7B〜13Bあたりから選ぶのが現実的だと思います。
量子化形式はGGUFのQ4_K_Mあたりが、品質とサイズのバランスが取れていておすすめです。
今回はその中からQwen3.5 9Bを選びました。理由は単純ですが、以下の通りです。
- 手持ちのMac(メモリ24GB)で快適に動かせるサイズの上限が、だいたいこのあたりであること
- コーディング用途のベンチマークで評判が良いこと
- 32Bも試したものの、レスポンスが体感で重く、補完用途には厳しかったこと
ローカルサーバーを起動する
ダウンロードが終わったら、サーバーを立ち上げます。
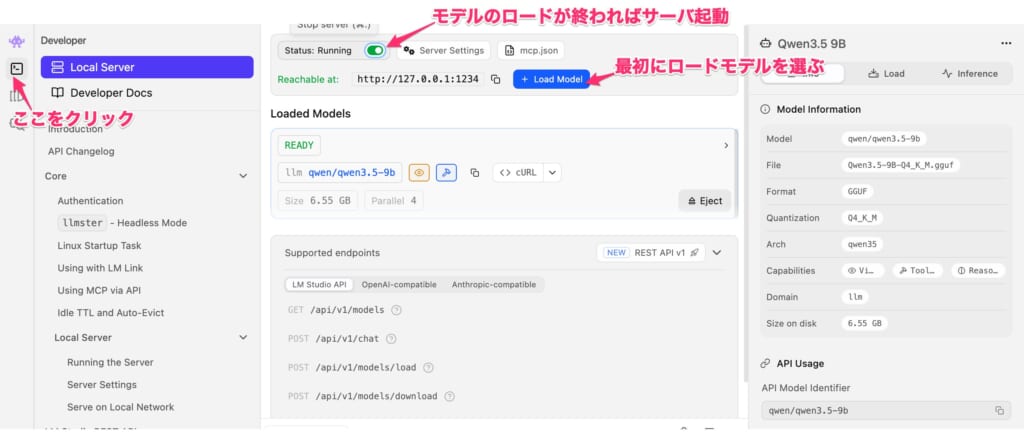
- 左メニューの「Developer」をクリックします。
- 「Load Model」ボタンを押し、ダウンロードしたモデルを読み込みます。
- 左上のトグルスイッチが「Status: Stopped」になっているので、ONに切り替えます。
- 画面下部のログに Server running on http://localhost
:1234と表示されれば成功です。
VSCode側の設定:Continueの導入と接続先設定
ここまででローカルサーバーが立ち上がっているので、あとはVS Code側から接続するだけです。Continueは設定ファイル1つで接続先を切り替えられるため、ローカルとクラウドを併用したい場合にも使いやすい作りになっています。
LM Studioへの接続設定
- VS CodeのアクティビティバーにContinueのアイコン(◯のロゴ)が追加されているので、クリックします。
- Continueパネルの設定アイコンから「Configure」を開きます
- config.yaml が開くので、以下のように models 配列を追記します
(既存の内容は消さずに追加してください)
name: Local Config
version: 0.0.1
schema: v1
models:
- name: LM Studio Local - qwen
provider: openai
model: qwen/qwen3.5-9b # LLM Studioのモデル名を正しく入力
apiBase: "http://localhost:1234/v1" # ポート番号はLLM Studioのポート番号を指定
apiKey: "1234" # APIキーはLLM Studioで設定してないが適当な値をセットする必要があるContinueの使い方
設定が完了すれば、Continueパネルからチャットを送るだけで、ローカルLLMが応答してくれます。
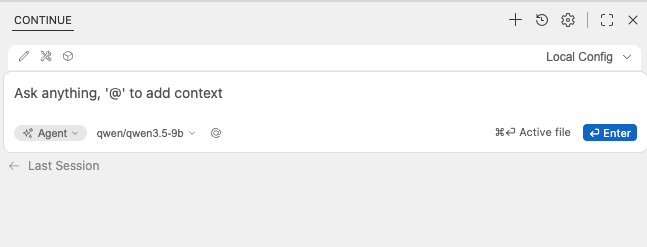
GitHub CopilotやCursorを使ったことがある方であれば、操作感はほぼそのままです。
違いは、モデルがローカルで動いていることくらいでしょうか。主な操作は以下の4つです。
| 操作 | ショートカット | 説明 |
|---|---|---|
| チャットで質問 | Ctrl + L | サイドバーでコードの説明・リファクタ・新機能提案などを依頼 |
| インライン編集 | Ctrl + I | コードを選択して「この関数を最適化して」など指示すると、その場で書き換え |
| オートコンプリート | Tab | コードを書いていると候補がゴーストテキストで出るので、Tabで確定 |
| コードベース全体をコンテキストに | Continueサイドバーで「Use codebase」 | リポジトリ全体を文脈に入れた回答が得られる。Cursorの「全体理解」と同じ用途 |
個人的によく使うのはインライン編集(Cmd+I)です。「ここをasync/awaitに書き直して」みたいな小さな依頼をコードから目を離さずに作業できるので気に入っています。
実際に使って感じたこと
Mac1台での運用には無理がある
最初はメインのMac(メモリ24GB)にLM Studioも入れて作業していたのですが、Qwen3.5 9Bをロードした時点で残りメモリが心許なく、ブラウザやビルドを並行させるとすぐにスワップが始まる状況でした。最終的には別PCにLM Studioを起動させ接続する構成に落ち着いています。
作業マシンと推論マシンは分けるのが無難だと思います。
クラウドと比べると速度面で見劣りする
応答速度に関しては、CopilotやClaudeと比べると明らかに遅いです。
サクサク感を求めるならクラウドの方が断然快適でした。
コード理解は予想以上に役立つ
一方で、9Bクラスでも関数単位のリファクタや「このメソッド何してる?」といったレベルの質問には十分対応してくれます。社外秘コードを扱う案件で手元のLLMが使えるというのは、思っていた以上に価値があります。
まとめ
ローカルLLMでのコーディング補助は、思いのほかしっかり動いてくれました。速度や精度ではクラウドAIにまだ及びませんが、コードを外部に出さずに済むというメリットは、案件によっては大きな価値になります。1年もすれば、ローカルLLMだけでかなりの作業をこなせるようになっているはずです。
今のうちに触れておく価値は十分にあります。
株式会社ウイングドアは福岡のシステム開発会社です。
現在、私達と一緒に"楽しく仕事が出来る仲間"として、新卒・中途採用を絶賛募集しています!
ウイングドアの仲間達となら楽しく仕事できるかも?と興味をもった方、
お気軽にお問い合わせ下さい!